

1. Definir el problema que se va a trabajar. (Aplicación )
2. Reconocer en el tipo problema, las variables involucradas.
3. Desarrollar el problema tomando en cuenta la teoría que se encuentra en la página.
4. Aplicar prueba de hipótesis a los resultados obtenidos.
5. Dar a conocer las conclusiones obtenidas a partir de las respuestas del problema.
6. Trabajar a partir de la hipótesis alternativa.
1. Definir el problema que se va a trabajar. (Aplicación )

En un empresa llamada "Centralita" están ofreciendo a sus usuarios el servicio de "soporte técnico". Para evitar que el usuario recurra a la competencia, han decidido investigar la manera para que el usuario no espere en el sistema más de un minuto. Para ello han pedido realizar este proyecto, con la esperanza de saber cuantos asesores son necesarios para este servicio ( para mantener los costos del servicio al mínimo sin presentar perdidas en la calidad del trabajo. )
Por datos estadísticos se sabe que el programa de soporte técnico se reciben en promedio
2. Reconocer en el tipo problema, las variables involucradas.
En este caso estamos trabajando bajo un modelo ERLANG - C, que se basa en un esquema FIFO, donde las llamadas en espera se van atendiendo a medida que los servidores se van liberando. Se asume que:
- Las llamadas llegan de forma aleatoria bajo una distribución de Poisson.
- Las llamadas se atienden según el orden de llegada.
- Las llamadas bloqueadas se colocan en una cola de espera de tamaño infinito.
- El tiempo de duración de las llamadas es de acuerdo a una distribución exponencial.
► Las variables aleatorias a considerar:
- Intensidad media de llegadas en un intervalo de tiempo t.
- Intensidad media de la duración de las llamadas
- Grado de servicio de la centralita.
- Cantidad de asesores para alcanzar el grado de servicio deseado.
3. Desarrollar el problema tomando en cuenta la teoría que se encuentra en la página.
Para comenzar con el desarrollo presentaremos las condiciones iniciales a través de los resultados obtenidos al tratar la información estadística registrada.Esto es para tiempo cumbre de trabajo.
Para comenzar con el desarrollo presentaremos las condiciones iniciales a través de los resultados obtenidos al tratar la información estadística registrada.Esto es para tiempo cumbre de trabajo.
 |
| Figura Nº1. Datos recolectados llamadas |
 |
| Figura Nº2. Distribución de llegada de llamadas al sistema ( Poisson ) |

λ = Tasa de arribo de llamadas por minuto ; λ = 4
μ = Tasa de servicio medio por minuto ; μ = 5
A = Intensidad de tráfico (en erlangs) [ E ] : A = λ * μ
► A = 20 [E]
O = Porcentaje ocupación del asesor ; O = ( A / N )*100
► O = 95.238 %

Donde P(>0) representa la probabilidad que tiene el usuario de encontrar el sistema ocupado en un instante t cualquiera.Aplicando este resultado para los valores enunciados en el problema se obtiene el valor:
P(>0) = 861996082.4 / { (271252262.9) + (861996082.4) }
P(>0) = (861996082.4) / (1133248345)
► P(>0) = 0.7606 ; y en porcentaje será P(>0) = 76.06 %
Luego la probabilidad de encontrar el sistema libre ( Pø ) será:
Pø = 1 - 0.7606
► Pø = 0.2394 ; y en porcentaje será Pø = 23.94 %
El siguiente paso será calcular el tiempo medio que demora un usuario en la cola ( Para verificar si es necesario el desarrollo del proyecto ).
D = Tiempo promedio de espera en la cola [ m ]

Tomando los datos del problema se tiene :
D = 0.7606 * 5
► D = 3.803 [ m ] ; en segundos será D = 228.18 [s]
El siguiente paso es calcular el porcentaje de usuarios que están esperando más de un minuto en la cola, y por tanto , abandonan el sistema por falta en la calidad en el servicio.
P(delay>t) = Es la función que representa el porcentaje de usuarios que esperan en el sistema más de cierto tiempo t. Es importante para en estos procesos, cuando se tiene en cuenta la variable de desesperación del usuario.

P( delay >1 ) = [ (0.7606) * (0.8187) ]*100 = 62.27 %
► P( delay >1 ) = 62.27 %
Con estos resultados podemos concluir que el 62.27% de los usuarios están saliendo del sistema debido a que consideran ineficiente el servicio ofrecido por la centralita.Lo que para la empresa representa una perdida muy importante de los usuarios.
Ahora evaluaremos el nivel de servicio real del servicio "soporte técnico"
C = Nivel de servicio real en la centralita.

C = 1- [ (0.7606)*(0.8187) ]
► C = 0.3772 ; y en porcentaje es C = 37.72 %

Ahora para realizar un estudio más eficiente de los datos, revisaremos que clase de distribución sigue la calidad de servicio, rectificando cun una prueba de bondad y ajuste; y al final dar los resultados con los que se trabajará la prueba de hipotesis.
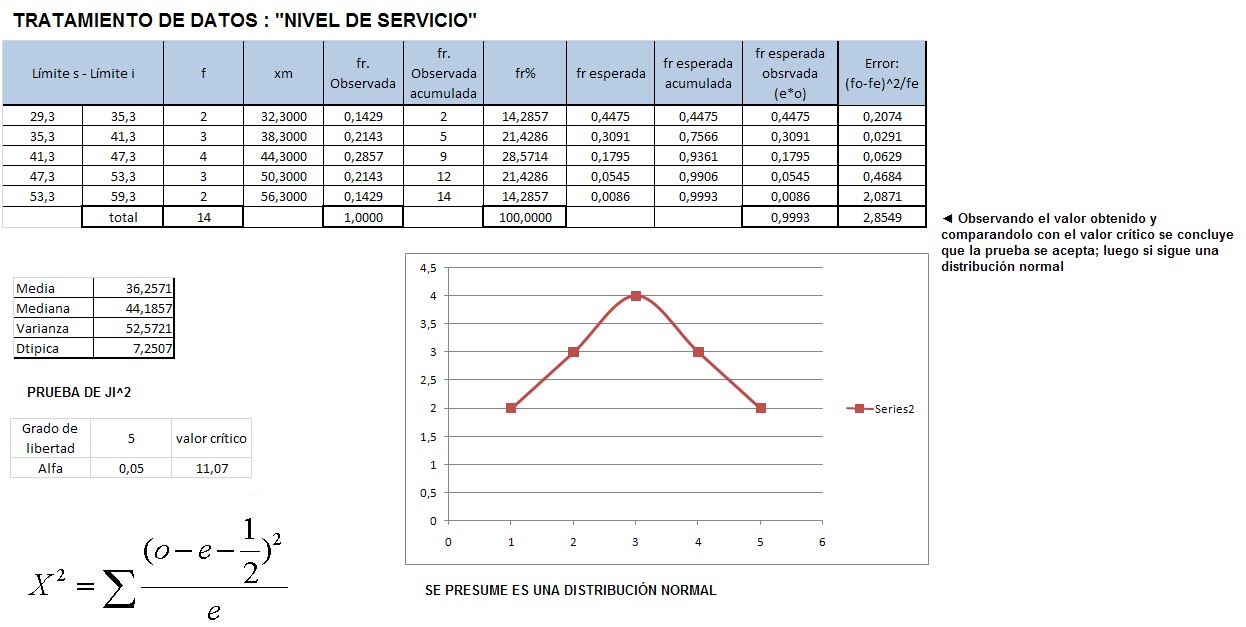
4. Aplicar prueba de hipótesis a los resultados obtenidos.
Comenzando con el tratamiento de los datos que se enseñan a continuación, se pretende demostrar que la calidad del servicio sigue una distribución normal ( esto por prueba de bondad y ajuste ) y para posteriormente hacer la prueba de hipótesis.
Para la prueba de hipótesis se tienen los siguientes datos:
Ho: C = 65
Ha: C < 65
μ =65 σ = 7.25
X= 36.25 (grado de libertad) k = 5
Para obtener los valores críticos para este trabajo, se asume trabajar con un intervalo de confianza del 5 % y por laboratorio virtual :
Z0.05 = 1.64
Trabajando con los datos obtenidos en este proyecto el resultado es:
Z0.05 = (36.25 - 65) / 7.25
Z0.05 = -3.965
Por lo tanto se rechaza la hipótesis nula y se acepta la hipótesis alternativa que dice: Ha: C < 65 %
5. Dar a conocer las conclusiones obtenidas a partir de las respuestas del problema.
Las conclusiones que se rescatan al terminar el desarrollo de este proyecto son:
- La estadística es una herramienta muy poderosa a la hora de tomar decisiones que beneficien o prevean el desarrollo de un trabajo en especial
- Los modelos de trabajo siempre pueden estar sujetos a una posible falla, por lo que hace indispensable, el revisar su funcionamiento.
- La teoría de colas es un método aplicable para una infinidad de problemas en nuestra carrera
- El modelo de trabajo Erlang - C es bastante útil, ya que evita al sistema tener una perdida de usuarios debido a la congestión en la cola
6. TRABAJANDO A PARTIR DE LA HIPÓTESIS ALTERNATIVA
Ahora el problema se resume a encontrar la cantidad de asesores necesarios en la centralita para que se cumpla que:
- El usuario en la cola no espere más de un minuto
- La calidad del servicio ( C ) sea igual o mayor 99% ; se considera un sistema excelente
- El asesor no este ocupado más de un 70 % de el tiempo
- El usuario pueda disponer de ayuda inmediata al ingresar al sistema
Calculadora de Erlang - C
Para ello usamos las ecuaciones vistas en el desarrollo del proyecto y la calculadora de Erlang - C para verificar los cálculos. Después se registran los datos en la siguiente tabla:

Para ello usamos las ecuaciones vistas en el desarrollo del proyecto y la calculadora de Erlang - C para verificar los cálculos. Después se registran los datos en la siguiente tabla:

No hay comentarios:
Publicar un comentario